1. Introduction
The TOAR Database Infrastructure is a hub for tropospheric ozone data rather than a classical data archive for such data. Times series data from established networks of stations as well as data from individual measuring stations is collected, curated, augmented with quality indicators, and stored permanently in the TOAR database. In case networks are later changing their data due to their curation process, it will again be collected, run through the ingestion process and changed in the TOAR database. Version numbers attached to the data and metadata as well as earlier published database dumps still reflect the previous status.
The individual measuring stations together with the managed and unmanaged networks of stations form the group of data producers. The TOAR management is done by the IGAC project activity TOAR (https://igacproject.org/index.php/activities/TOAR), specifically by the Steering Committee of TOAR Phase-II, and the designated community is the TOAR community, more general all researchers who analyse tropospheric ozone data with respect to the global-scale impact of ozone on climate, human health and crop/ecosystem productivity.
In the following the key components of the TOAR Data Centre are defined:
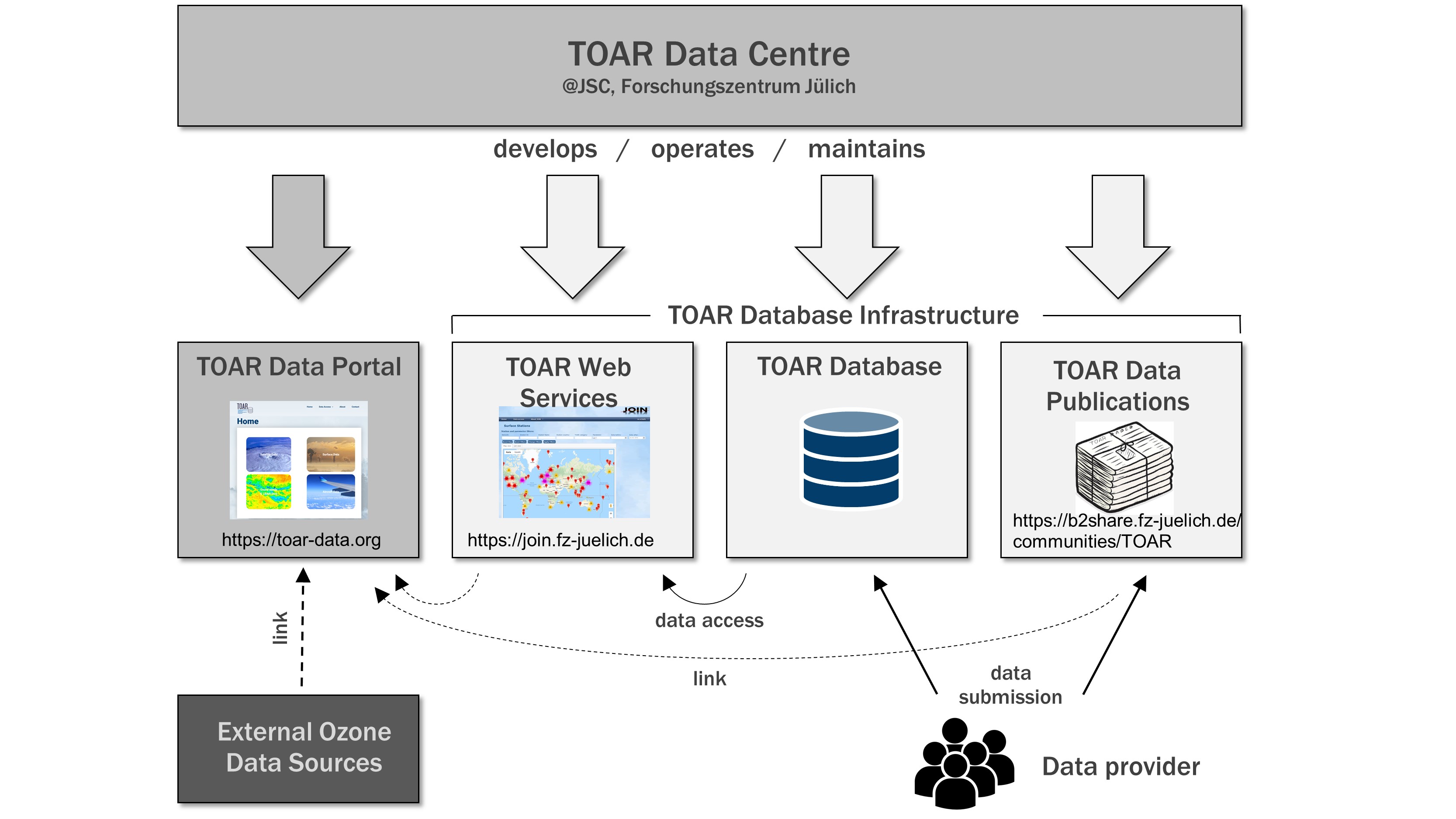
Fig. 1.1 Overview of the TOAR Data Centre Components
The TOAR Data Centre (TOAR DC) comprises services and data in support of the Tropospheric Ozone Assessment Report activity. Its main goal is to provide access to tropospheric ozone data for research on the global-scale impact of ozone on climate, human health and crop/ecosystem productivity. A subset of its components build the TOAR Database Infrastructure.
The TOAR Database gets data from individual stations, which are curated before stored, and harvests data from measurement station networks. It provides an API for (data ingest and) data access. Publicly available data from relevant networks such as UBA (German Environment Federal Office) or OpenAQ (https://openaq.org) are downloaded, harmonised, and quality checked before they are stored in the TOAR database. These data might change over time at their origin because of the providers’ own curation processes, which means that they will subsequently be changed in the TOAR database. The data from individual providers are formatted according to the TOAR submission guidelines and contain the requested metadata. In the ingestion process the data are curated and enriched by other metadata. The curated data and metadata are sent to the providers for approval before they are stored and published in the TOAR database.
The TOAR Data Portal provides access to various external ozone data sources and to the TOAR database by linking to the respective web services.
The TOAR Web Services provide the REST interface for accessing the TOAR database.
The TOAR Data Publication Service enables the TOAR data curators to publish data from individual providers to an external service B2SHARE at Forschungszentrum Jülich. In this process the necessary metadata for the publication is generated automatically through a query to the TOAR database and mapped to the B2SHARE metadata fields. (B2SHARE is the EUDAT user-friendly, reliable and trustworthy service for researchers, scientific communities and citizen scientists to store and publish research data from diverse contexts).
All TOAR Database Infrastructure services are run on hardware and software which is installed and maintained at JSC (Jülich Supercomputing Centre, www.fz-juelich.de/ias/jsc), a section of the Institute for Advanced Simulation (IAS) at Forschungszentrum Jülich. They make use of general computer centre tools and services such as Tivoli Storage Manager (TSM) for backup, archiving and hierarchical storage management, which are implemented to serve all systems in the supercomputer centre and on Forschungszentrum Jülich campus.